需要予測とは何ですか?
組織が過去に行った出荷を推定することで、あらゆる製品の需要を予測できます。これにより、潜在的なビジネスを失わずに、同時に生産スケジュールを積極的に最適化することができます。 過剰在庫に投資しないことで、キャッシュフローが改善され、過剰在庫の可能性が低くなります。需要を予測するこのプロセスは、しばらく前から行われていますが、ほとんどの場合、ビジネス アナリストが需要を予測しようとするかなり無計画で場当たり的なアプローチでした。 単純な時系列アルゴリズムを使用すると、これを実行する従来のプロセスでも、履歴データセットを活用するだけで済みました。 現在では、最新のクラウドと Apache Spark などのインメモリ ビッグ データ エンジンの力を利用して、次のような需要の一部を促進する原因となる可能性のある外部要因を相互に関連付けることもできます。
人口統計、
気象条件
競争の影響。
この相関関係により、需要に対するより良い洞察が得られる傾向があり、それによって精度が向上し、さらに次のような最新の AI/ML アルゴリズムをすべて活用できるようになりました。
ランダムフォレスト、
勾配ブースティング
ニューラルネットワーク
従来の時系列アルゴリズムと比較して、企業データに対して大規模に実行できます。
需要を予測する方法論
Azure Databricks (Apache Spark のマネージド サービス) などのスケーラブルな分散プラットフォームで最新かつ最高のアルゴリズムをすべて適用できるように、まず SAP ERP から Azure のエンタープライズ データを取得する必要があります。 データを Azure に取得した後、データのクリーニング/マッサージを開始して、その上で予測機械学習モデルをトレーニングします。 モデルをトレーニングした後、Power BI などの包括的な BI ツールで予測を視覚化し、サード パーティのアプリケーションから予測を呼び出せるようにモデルを Azure ML にデプロイします。
したがって、簡単に要約するために、次のことを行います。
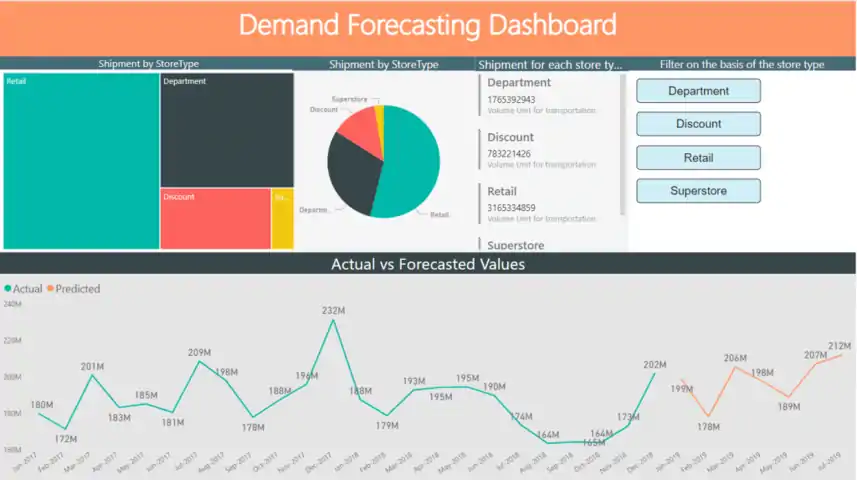
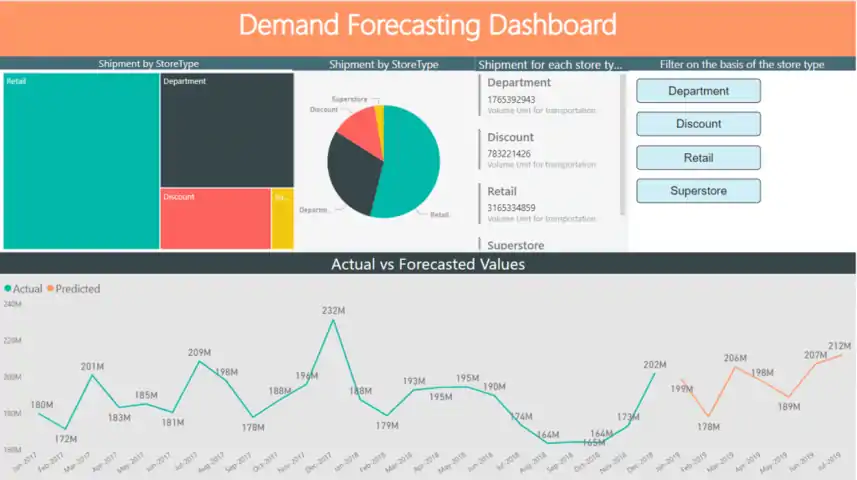
PowerBI ダッシュボード
Azure Data Factory と呼ばれるマネージド ETL/ELT サービスを使用して Azure にデータを取り込む
Spark データ フレームで Azure Data Lake からデータを読み取る
Azure Databricks で機械学習モデルをトレーニングする
Power BI で結果を視覚化する
Azure ML にモデルをデプロイする
詳細な手順:
Azure Data Factory パイプライン
[/vc_column_text]
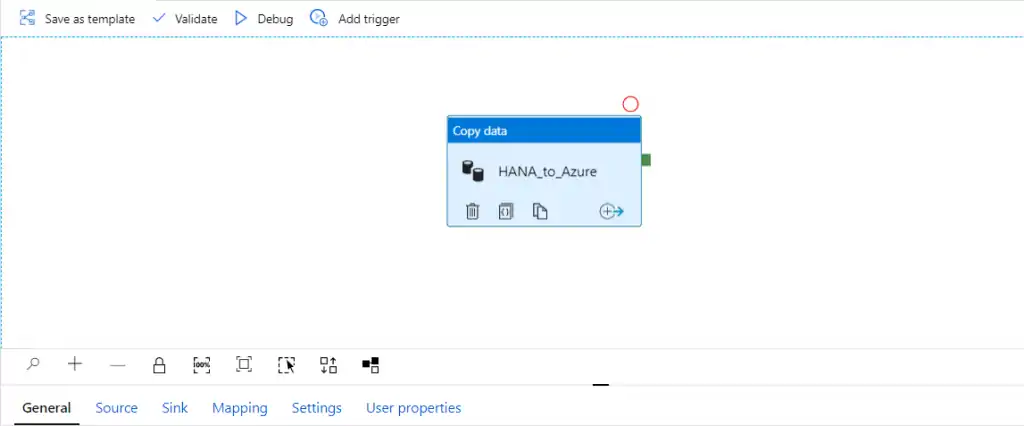
[/vc_column][/vc_row]
上の画像に示されているパイプラインでは、ソースは SAP HANA であり、Azure Data Factory で標準オファリングとして提供される HANA コネクタを使用しています。

Databricks ノートブック
データが Azure Data Lake に入力されたら、1 行のコードで Spark データ フレーム内のデータの読み取りを開始します。


Spark データ フレーム内の SAP データ
この後、非常に単純な Spark ベースの変換を適用して、カテゴリ変数を数値変数に変換して、その上に機械学習モデルを構築できるようにします。 このシナリオでは、Apache Spark MLlib を使用して GBT 回帰を使用し、
最後にモデルをトレーニングして予測を行い、結果を Databricks グラフですばやく視覚化します。

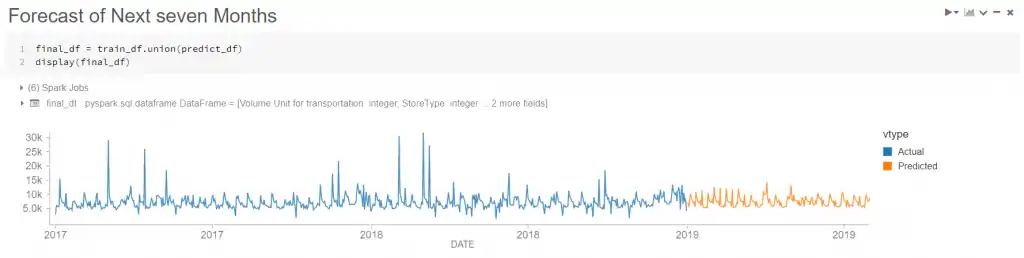
ML モデルの結果を簡単に視覚化
Power BI ダッシュボード
Databricks を使用して、予測結果を Azure SQL Database に入力し、Power BI ダッシュボードで視覚化します。