ما هو التنبؤ بالطلب؟
يمكن التنبؤ بالطلب على أي منتج من خلال تقدير الشحنات التي قامت بها المنظمة في الماضي، وهذا يسمح لنا بتحسين جدول الإنتاج لدينا بشكل استباقي حتى لا نفقد أي أعمال محتملة وفي نفس الوقت لا نخسر أيضًا. إذا كنت تستثمر في المخزون الزائد مما يؤدي إلى تدفق نقدي أفضل واحتمال أقل لتكدس المخزون، فإن عملية التنبؤ بالطلب كانت موجودة منذ فترة من الوقت الآن ولكن في الغالب كانت طريقة عشوائية جدًا ومخصصة حيث يحاول محللو الأعمال التنبؤ بالطلب باستخدام خوارزميات السلاسل الزمنية البسيطة، فإن العملية التقليدية للقيام بذلك تتضمن فقط الاستفادة من مجموعات البيانات التاريخية. الآن بفضل قوة السحابة الحديثة ومحرك البيانات الضخمة الموجود في الذاكرة مثل Apache Spark، يمكننا أيضًا ربط أي عوامل خارجية قد تكون مسؤولة عن تحفيز جزء من طلبنا مثل:
الديموغرافيا,
احوال الطقس
تأثير المنافسة.
تميل هذه العلاقة المشتركة إلى منحنا رؤية أفضل لطلبنا مما يؤدي إلى دقة أفضل، علاوة على أنه يمكننا الآن الاستفادة من جميع خوارزميات الذكاء الاصطناعي/التعلم الآلي الحديثة مثل:
غابة عشوائية,
تعزيز التدرج
الشبكات العصبية
وتشغيلها على نطاق واسع على بيانات مؤسستنا مقارنة بخوارزميات السلاسل الزمنية التقليدية.
منهجية التنبؤ بالطلب
نحتاج أولاً إلى الحصول على بيانات المؤسسة الخاصة بنا في Azure من SAP ERP حتى نتمكن من البدء في تطبيق جميع الخوارزميات الأحدث والأفضل في نظام أساسي قابل للتطوير وموزع مثل Azure Databricks (الخدمة المُدارة لـ Apache Spark). بعد إدخال البيانات إلى Azure، نبدأ في تنظيف/تدليك البيانات لتدريب نموذج التعلم الآلي التنبؤي عليها. بعد تدريب النموذج، نقوم بتصور التوقعات على أداة ذكاء الأعمال الشاملة مثل Power BI وننشر النموذج أيضًا على Azure ML حتى نتمكن من استدعاء توقعاتنا من أي تطبيق تابع لجهة خارجية
لذا، لكي نلخص الأمر بسرعة، سنقوم بما يلي:
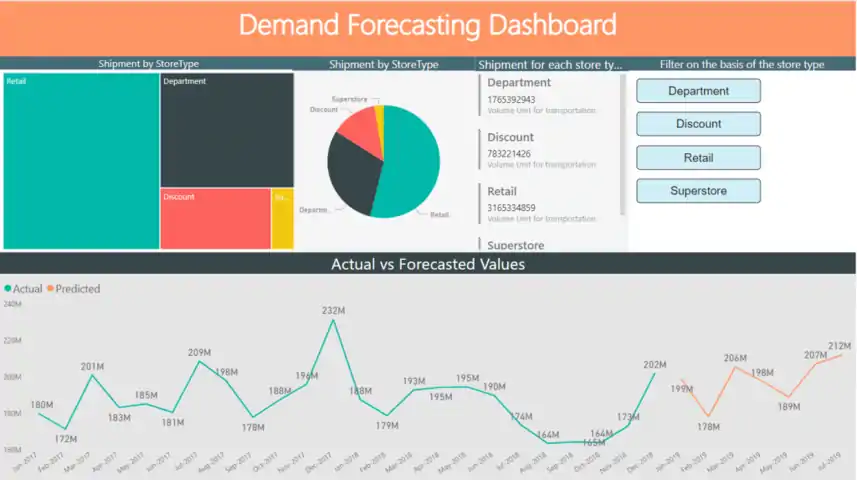
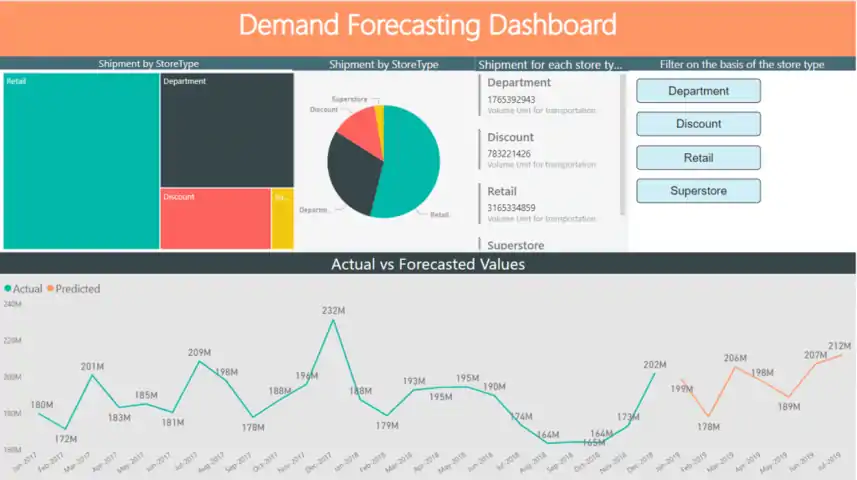
لوحة تحكم PowerBI
اسحب البيانات إلى Azure باستخدام خدمة ETL/ELT مُدارة تسمى Azure Data Factory
اقرأ البيانات من Azure Data Lake في إطار Spark Data
تدريب نموذج التعلم الآلي في Azure Databricks
تصور النتائج على Power BI
انشر النموذج على Azure ML
الخطوات التفصيلية:
خط أنابيب مصنع بيانات Azure
[/vc_column_text]
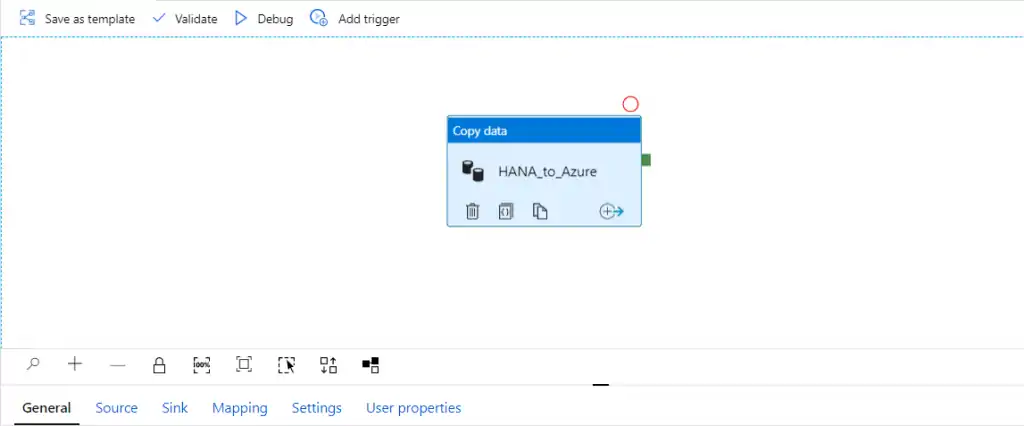
[/vc_column][/vc_row]
في المسار الموضح في الصورة أعلاه، مصدرنا هو SAP HANA ونحن نستخدم موصل HANA المتوفر في Azure Data Factory كعرض قياسي

دفاتر ملاحظات Databricks
بمجرد دخول البيانات إلى Azure Data Lake، نبدأ في قراءة البيانات الموجودة في Spark Data Frames باستخدام سطر واحد من التعليمات البرمجية


بيانات SAP في إطار بيانات Spark
بعد ذلك، سنقوم بتطبيق تحويلات بسيطة للغاية تعتمد على الشرارة حيث نقوم بتحويل المتغيرات الفئوية إلى متغيرات رقمية حتى نتمكن من بناء نموذج التعلم الآلي عليها. في هذا السيناريو، سنستخدم انحدار GBT باستخدام Apache Spark MLlib ثم نتنبأ بـ
لقد قمنا أخيرًا بتدريب النموذج ولدينا توقعاتنا وتصور النتائج بسرعة في الرسم البياني لـ Databricks

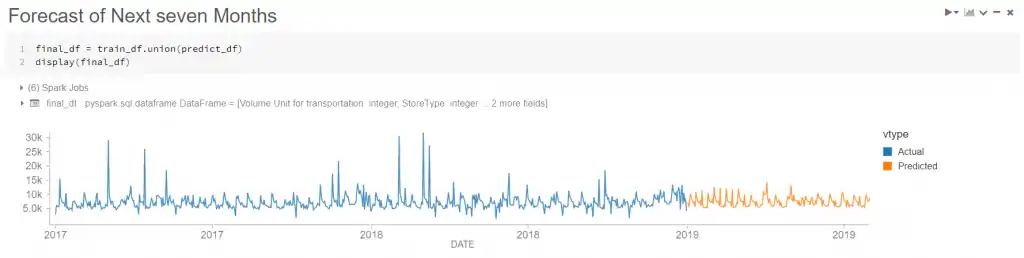
تصور سريع لنتائج نموذج ML
لوحة تحكم Power BI
باستخدام Databricks، نقوم بملء نتائج التنبؤ في قاعدة بيانات Azure SQL ثم تصورها على لوحة معلومات Power BI.